
’m sure Chat GPT is already very familiar to everyone being released last year in November of 2022 by company Open AI. So since then it’s become the fastest growing consumer software application in history by gaining more than 100 million users. I’m sure many of them were school students trying to cheat on their history essays but regardless it raised Open AI’s worth to 29 million USD.
The chat GPT bot operates on a large language model made by Open AI called GPT which was specifically made for conversational apps. GPT’s full form is generated pre-trained transformer. It can generate human-like responses to queries, it is enhanced with training in a myriad of datasets and human trainers and transformer is the large language model which is the background architecture for chat gpt as well as many other AI bots. Although Chat GPT may be the most popular, other AI applications from Open AI include Dall-E 2 for art generation and Whisper, a speech recognition software.
Here is a basic diagram of how Chat GPT works to provide input in the backend.
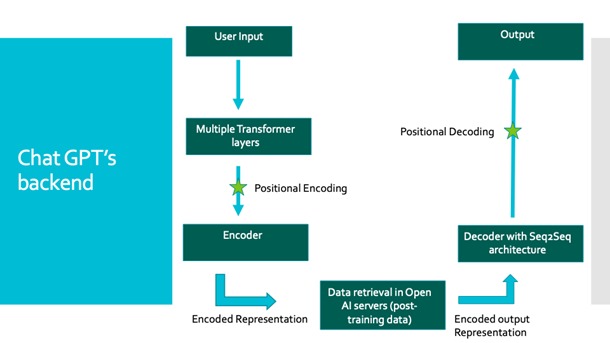
If you ask the app to write you an essay on capitalism, you’ll get your result but what would it do in the background?
Once you enter in any input, it’s sent to a background of multiple layers of the language model transformer in order to process your input and encode it into a high dimensional representation. This is done through an encoder using positional encoding. This means it’s taking every word of the input and translating it into individual vectors which the language model understands. This encoded representation is taken to Open AI’s servers so the software can compare its encoded vectors to vectors of data it’s already understood from training.
Now that an output is in hand, it’s taken to a decoder using a sequence to sequence architecture to decode the output again word by word before returning it back to the user.
Training
This process lets you get from input to output, but for the most important step, data retrieval, the model first needs to be trained.
Chat GPT version 4 is trained in ~ 45 TB of data by human trainers with unsupervised learning so it can understand patterns in the data it is fed. When training, the model is fed large amounts of text data and adjusting its trillions of parameters accordingly. The goal of this training is to minimize a loss function so the difference between the actual output and the desired output is as less as possible. It is also trained by a variant of stochastic gradient descent optimization to update its parameters based on the loss function and these training processes will continue until the performance of the language model is no longer improving.
This is just the top level of what’s going on with Chat GPT but competitors like Bard from Google and Llama from Meta also use similar models to produce results. In all I think Chat GPT is really useful for so many things, for example school children with access to Chat GPT don’t have to use the program to cheat, but can study with it. Ask it to create a practice quiz for you on a certain subject or summarize a concept you didn’t understand from your teacher.
Chat GPT can be incredibly useful to so many people worldwide and new use cases are constantly being discovered